I share insights on big data technologies and algorithms, drawing from my hands-on experience as a data engineer and in-depth research from scientific papers to enhance my expertise.
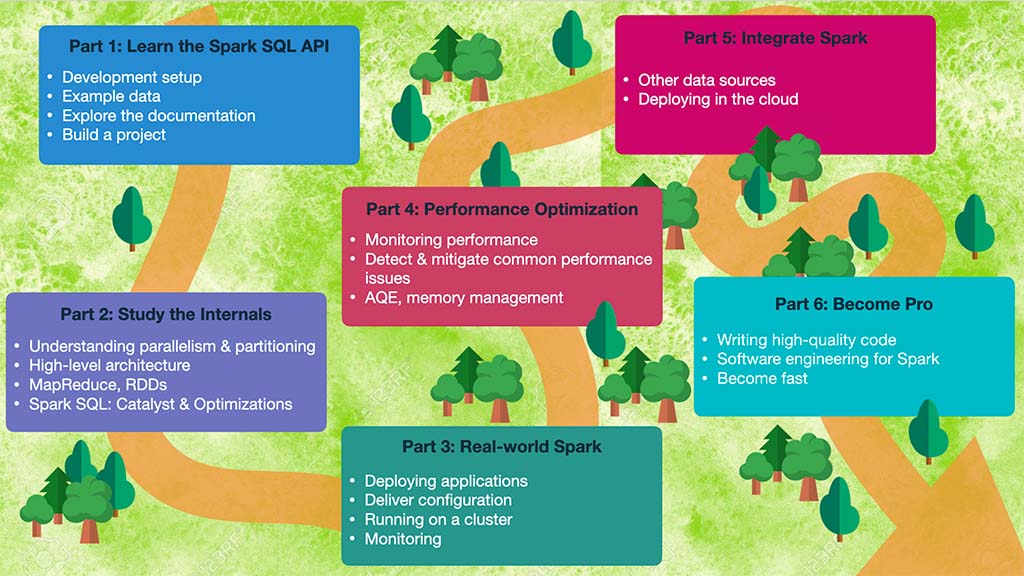
Aspiring to become Pro can be a daunting goal. One may easily feel confused and overwhelmed. What you need is a crystal-clear roadmap to success; And I help you craft yours.
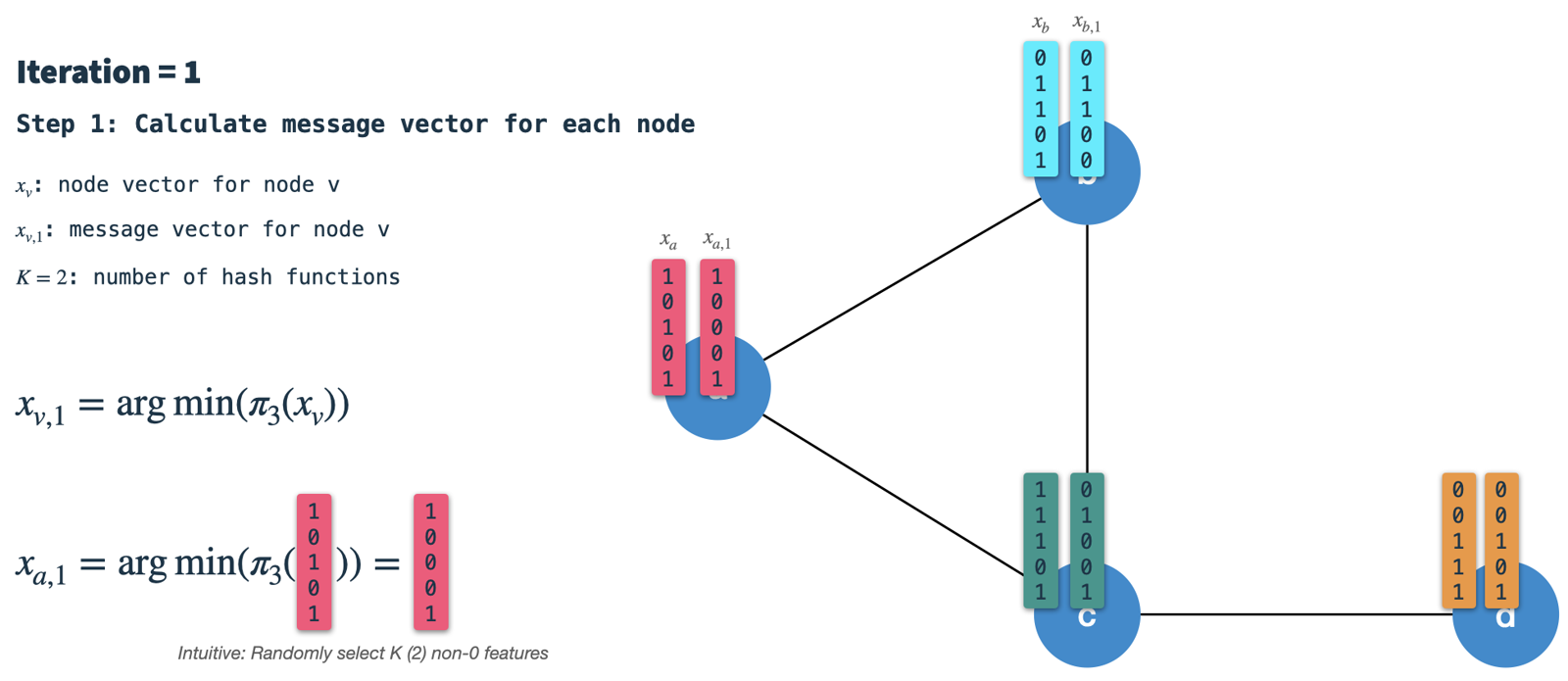
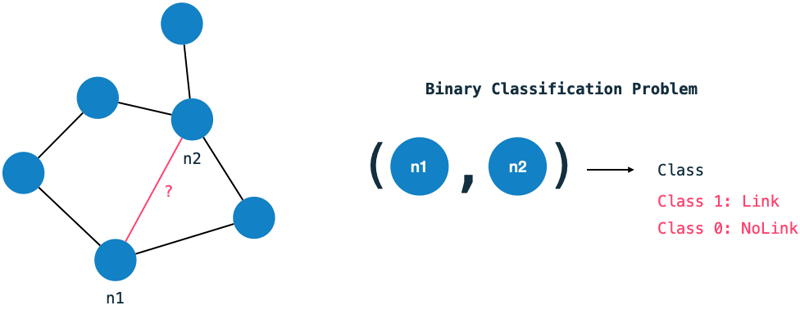
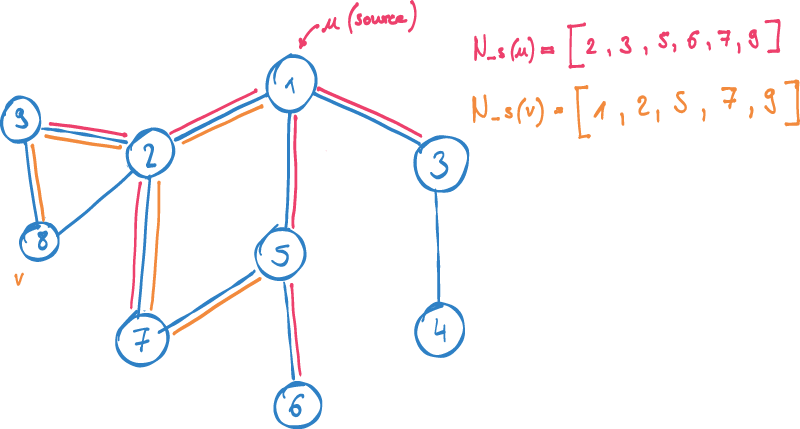
HashGNN (#GNN) is a node embedding technique, which was recently implemented in the Neo4j GDS (Graph Data Science Library). In this article, we will understand what all of that means and will explore how the algorithm works using a small example.
The Neo4j GDS Machine Learning pipelines are a convenient way to execute complex machine learning workflows directly in the Neo4j infrastructure. In this article, I elaborate on the main concepts and pitfalls of working with such a pipeline.
We created a recommendation engine to predict the area for a task in DayCaptain. We followed a simple approach and it works astonishingly well - even compared to complex approaches like deep NNs. The solution can be implemented in a handful lines of Cypher and runs directly in Neo4j - no overhead for managing additional systems. In this article, I describe the easy maths and how it works.
Understand how node2vec maps graph-structured data to numerical vectors - the key to unlock the powerful toolbox of traditional machine learning algorithms for graphs.
One question that I have come across many times recently, and which have given some careful thought is: What's the deal about graph databases and how are they different?
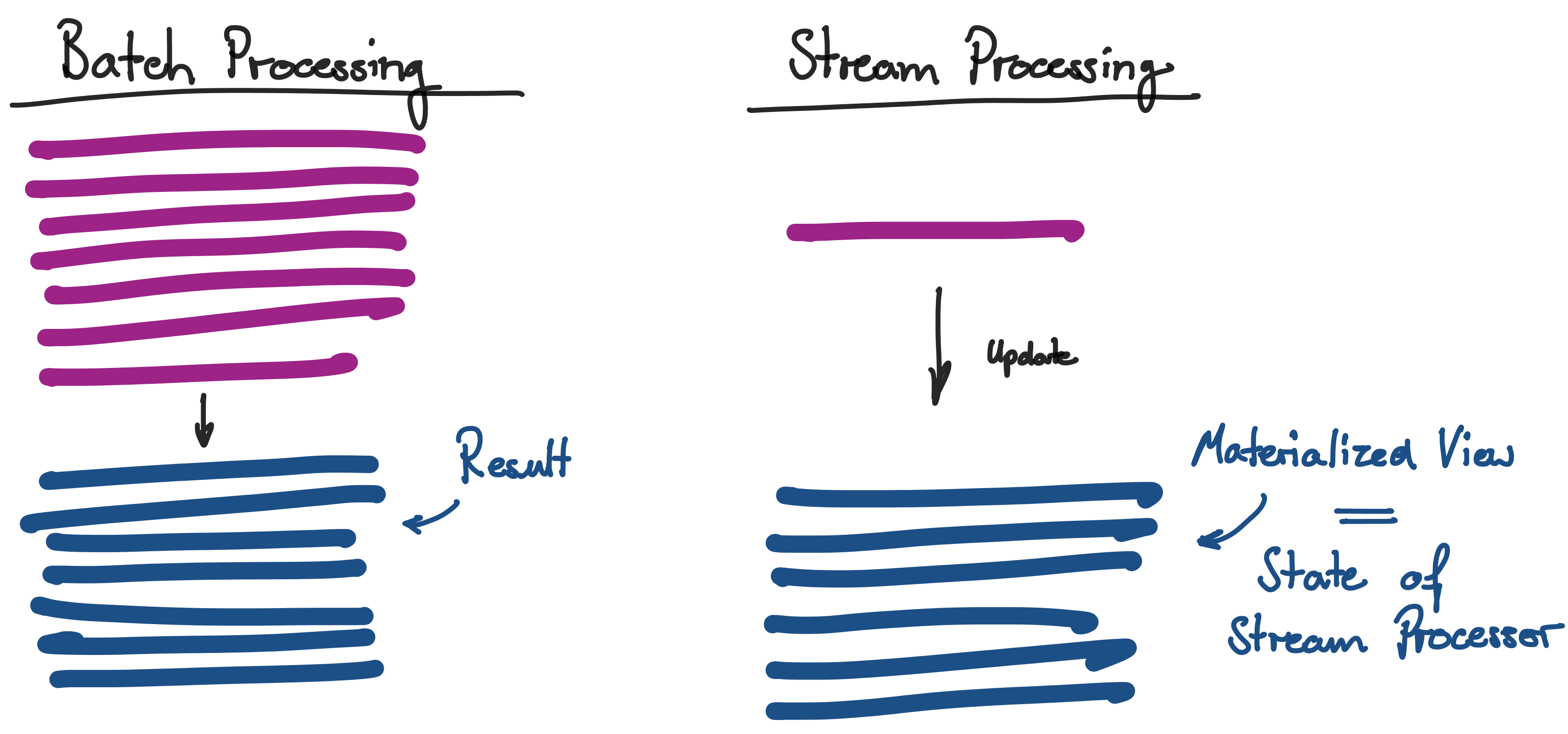
Today, new technologies arise and new things become possible. People are talking about stream processing and real-time data processing. Everyone wants to adopt to new technologies to invest in the future. Even though I personally think this is a reasonable thought, I am also convinced that one has to understand these technologies first and what they were intended to be used for.
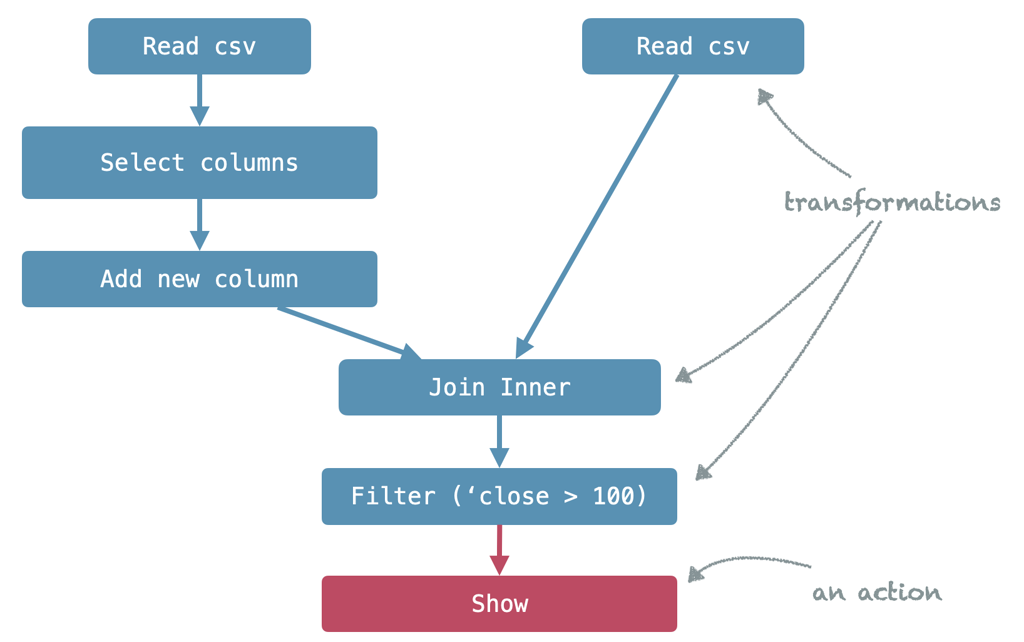
Apache Spark's high-level API SparkSQL offers a concise and very expressive API to execute structured queries on distributed data. Even though it builds on top of the Spark core API it's often not clear how the two are related. In this post I will try to draw the bigger picture and illustrate how these things are related.
One essential choice to make when building data-driven applications is the technology of the underlying data persistence layer. Let's explore their criteria.
As described in Understanding Spark Shuffle there are currently three shuffle implementations in Spark. Each of these implements the interface ShuffleWriter. The goal of a shuffle writer is to take an iterator of records and write them to a partitioned file on disk - the so called map output file.
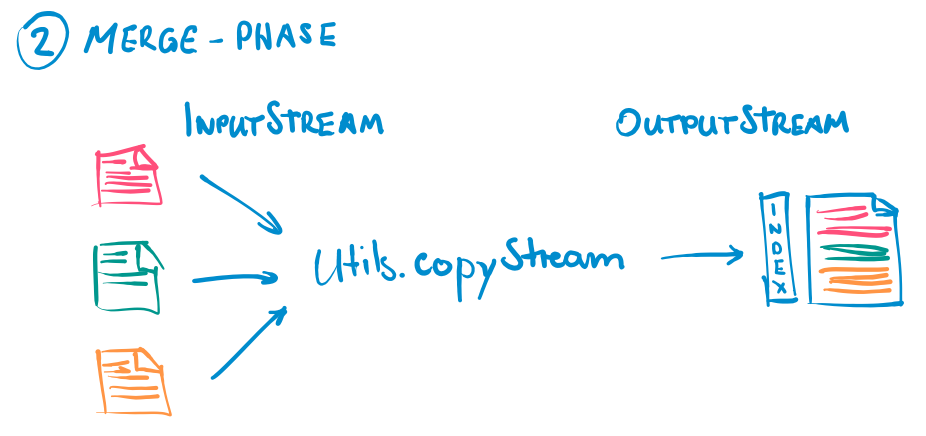
This article is dedicated to one of the most fundamental processes in Spark - the shuffle. To understand what a shuffle actually is and when it occurs, we will firstly look at the Spark execution model from a higher level. Next, we will go on a journey inside the Spark core and explore how the core components work together to execute shuffles. Finally, we will elaborate on why shuffles are crucial for the performance of a Spark application.